No matter how you feel about “AI”, these tools are here to stay, or at least for the time being, and Microsoft is definitely pushing them hard on Azure and with other products. While I’m partly in the camp of “solutions looking for a problem,” some of these tools are sure to streamline work in the future. I’m not sure if this specific one is one of them, but let’s start easy and look into text analytics and Azure AI Services Containers.
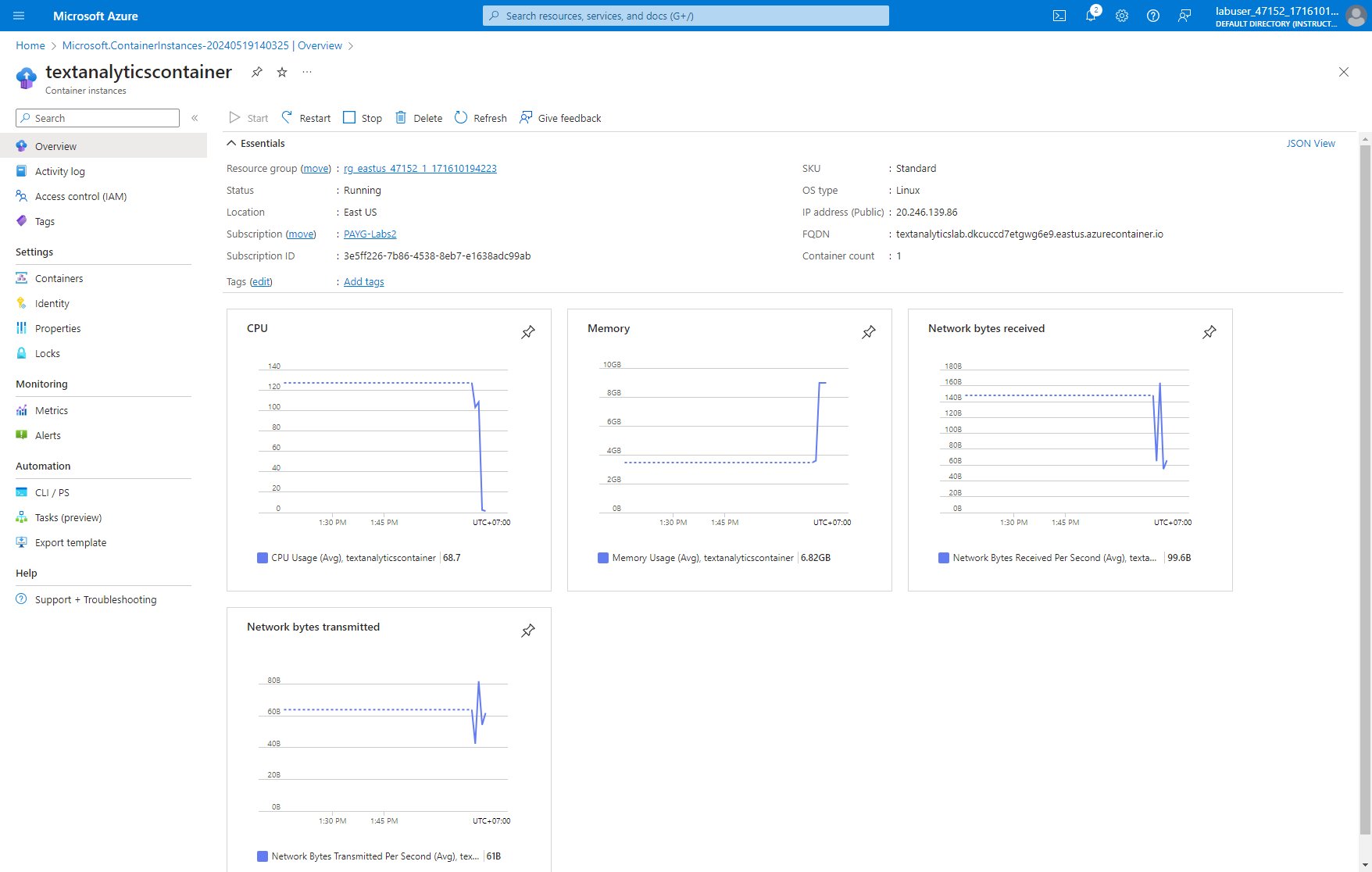
Azure AI Multi-service Account
Now that’s a mouthful, but essentially, the multi-service account does really what it says on the tin: it provides access to Vision, Language, Search, Speech and other AI services on Azure with a single API key. This makes it easy to play around with these containerized labs, so we’ll start off by creating a multi-service account, which we then use to actually handle all the connectivity of the text analytics container that is to follow.
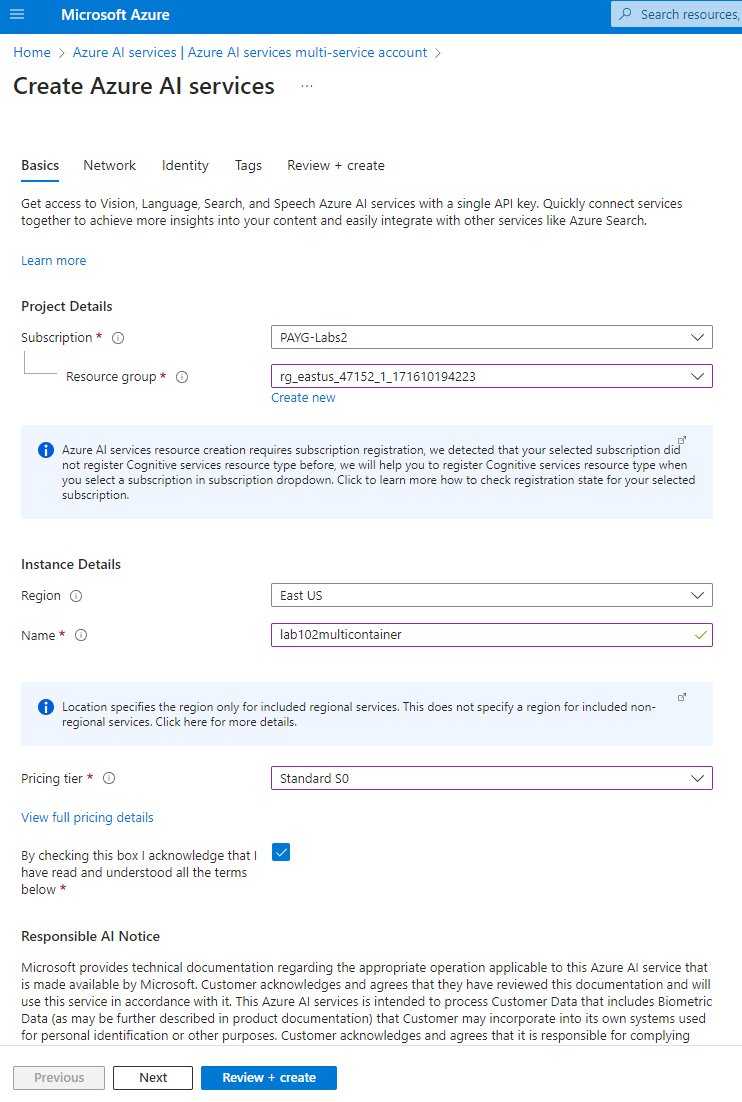
As usual with Azure services, there’s not that much to do in order to get things up and running, and we essentially just need to select our region, resource group level name, and pricing tier. Once the account is deployed, we can navigate to Keys and Endpoint to fetch KEY and the Endpoint URL. These will be passed to the container as environment variables so that it can make the connection to the relevant AI service.
Deploying the Container Instance
This is a step that could actually be done locally as well with Docker, so taking care to specify the API key, Endpoint URL and EULA acceptance, you could just as well run this locally with the following:
1
2
3
4
5
6
7
8
9
docker run \
--rm -it \
-p 5000:5000 \
--memory 10g \
--cpus 1 \
mcr.microsoft.com/azure-cognitive-services/textanalytics/language:latest \
Eula=accept \
Billing=<EndpointURL> \
ApiKey=<APIKey>
However we’ll be using Azure which breaks this process down a bit, so
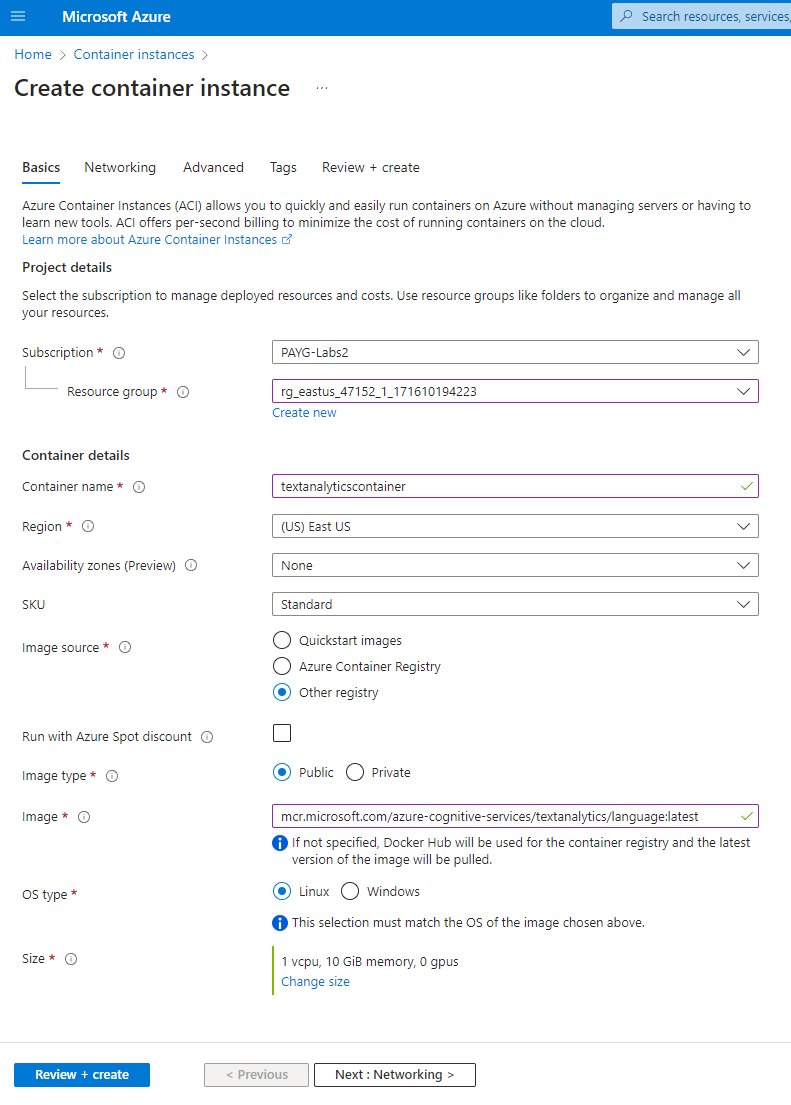
Container instance - Basics
We just need to name our instance, set the image registry to match mcr.microsoft.com/azure-cognitive-services/textanalytics/language:latest and up the instance memory to 10 GiB, since we’ll be almost hitting that so the default 1.5 GiB won’t exactly do.
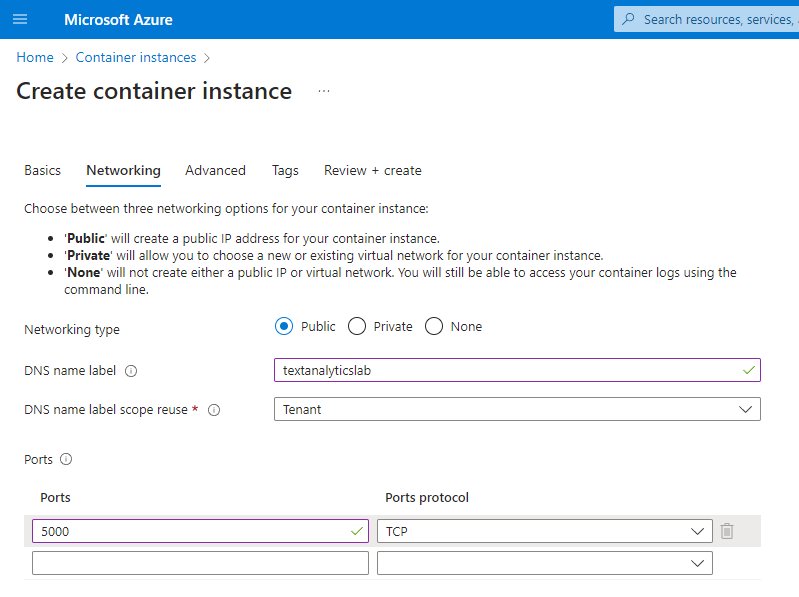
Container instance - Networking
While the Docker run command just needs the -p flag, here we need to play around a little more. Also, don’t forget to make sure that you’re setting the Networking type to public to enable public access to the container. And conversely, if you don’t want that to be the case in your environment, do the opposite.
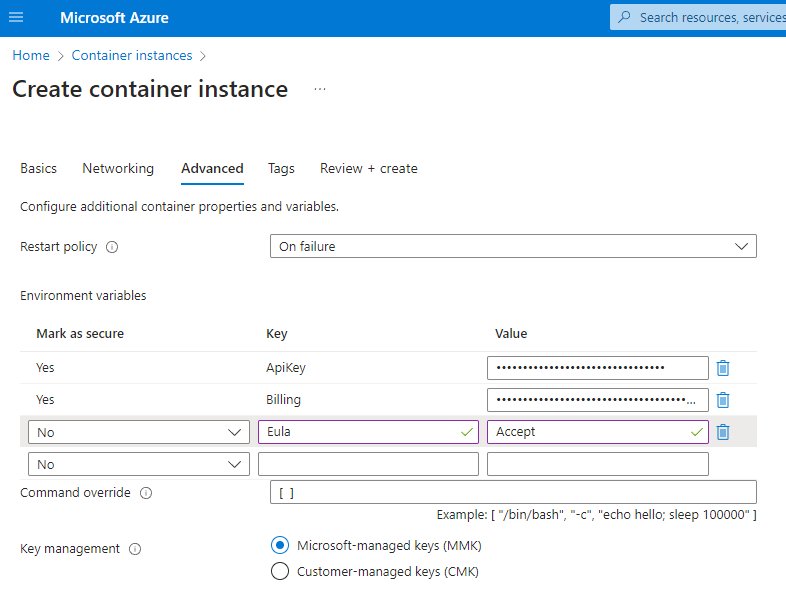
Container instance - Advanced
Finally, the Advanced settings, which are really just the environment variables. The following key/value pairs need to be set:
ApiKeyBilling(the Endpoint URL)Eula
The key management can be left to Microsoft to handle. And off we go!
Doing Text Analytics and Having Some Fun
Now that the container is up and running, we just need to grab the FQDN, or fully qualified domain name, or the IP address to be able to make connections to the container and AI text analytics service. For this, we’ll just be using curl, and since I’m rather linguistically challenged, I’ll ask Copilot to generate me some sentences I can try to match against the service. If the sentences are grammatically incorrect, blame Copilot.
1
2
3
curl -X POST "http://<ContainerAddress>.eastus.azurecontainer.io:5000/text/analytics/v3.0/languages" \
-H "Content-Type: application/json" \
--data-ascii "{'documents':[{'id':1,'text':'Mirëdita! Si jeni? Unë shpresoj që keni një ditë të mbarë.'},{'id':2,'text':'¡Hola! ¿Cómo estás? Espero que todo esté bien contigo.'}]}"
So, what’s going on here?
First, we’re just making a POST request to our container, and passing some header information. Then we’ll follow that with a couple sentences that we’re aiming to figure out the language of.
Assuming all goes well, we’ll get the following JSON response:
1
{"documents":[{"id":"1","detectedLanguage":{"name":"Albanian","iso6391Name":"sq","confidenceScore":1.0},"warnings":[]},{"id":"2","detectedLanguage":{"name":"Spanish","iso6391Name":"es","confidenceScore":1.0},"warnings":[]}],"errors":[],"modelVersion":"2024-04-01"}
It seems like Azure is completely confident (1.0) that the first language is Albanian and the second one is Spanish. It sounds about right. Let’s try something else.
1
2
3
curl -X POST "http://<ContainerAddress>.eastus.azurecontainer.io:5000/text/analytics/v3.0/languages" \
-H "Content-Type: application/json" \
--data-ascii "{'documents':[{'id':1,'text':'你好!你今天过得怎么样?'},{'id':2,'text':'안녕하세요! 오늘은 어떠셨나요?'}]}"
Response:
1
{"documents":[{"id":"1","detectedLanguage":{"name":"Chinese_Simplified","iso6391Name":"zh_chs","confidenceScore":0.13},"warnings":[]},{"id":"2","detectedLanguage":{"name":"Turkmen","iso6391Name":"tk","confidenceScore":0.97},"warnings":[]}],"errors":[],"modelVersion":"2024-04-01"}
The first one says Simplified Chinese, and I suppose that’s correct. However, Turkmen? I’m quite sure that’s Korean, so I’m not really sure where the quite high confidence comes from. I think I should be using some encoding settings there, though, so the text that’s passed in is getting sent incorrectly, but it did get Chinese correct with very low confidence… Anyhow, this makes me think that we could maybe have some fun with the detection, try to see if we can make it really fail.
1
2
3
curl -X POST "http://<ContainerAddress>.eastus.azurecontainer.io:5000/text/analytics/v3.0/languages" \
-H "Content-Type: application/json" \
--data-ascii "{'documents':[{'id':1,'text':'Miltee se tuntus vielä joskus muata meijän sukuhauvassa? Missee piruntorjuntapunkkerj on?'},{'id':2,'text':'Tämän nedälin sanazet ollah kezä, kezäine da kezähine. Kezä on ‘kesä’, kudai voibi olla kui iččenäzenny sanannu, mugai yhtyssanan vuitinnu, kui suomengi kesä.'}]}"
The first one is Savonian dialect from Eastern Finland. I found these examples over at http://users.jyu.fi/~kirkopo/savo/?sivu=sanakirja. The next one is a Karelian dialect sample from the blog of University of Eastern Finland: https://blogs.uef.fi/karjalanelvytys/sananen-karjalaksi/. Let’s see how Azure fares with those.
1
{"documents":[{"id":"1","detectedLanguage":{"name":"Finnish","iso6391Name":"fi","confidenceScore":0.98},"warnings":[]},{"id":"2","detectedLanguage":{"name":"Finnish","iso6391Name":"fi","confidenceScore":0.98},"warnings":[]}],"errors":[],"modelVersion":"2024-04-01"}
Well, hot diggety dog! I mean, they could definitely be more accurate, and someone is bound to get angry at Karelian being called a Finnish dialect, but considering that neither is, for maybe rather obvious reasons, a supported language, I think the results are quite accurate.
Conclusion
Language detection alone isn’t really a very useful thing, as for the most part, it’s not really knowing what a specific language is that’s the main goal for the end user, but this is how all those automatic detections you might have seen around are working. In that sort of use, you can cut down lots of work and selections by simply automating the detection, and while things aren’t necessarily perfect, they’re definitely high up there and getting better all the time.